In the earliest computer systems memory was assigned in single, contiguous regions
We saw that the earliest computer systems operated on a memory model that required that all of the memory required by a given process be allocated to it in a single, contiguous region of physical memory.
Paging and/or segmentation can allow us to relax this requirement, but requires special hardware
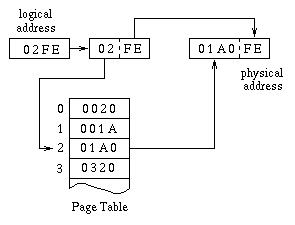
Last lecture, we saw that this requirement could be relaxed to allow non-contiguous allocation of physical memory by using paging and/or segmentation techniques. Central to any such approach is the concept of mapping logical addresses generated by the process into actual physical addresses by special hardware, which makes use of information stored either in special registers or in a page/segment table in memory.

-
Such a mapping scheme leads to a distinction between two different address spaces:
-
logical address space
The logical address space is the range of logical addresses that can be generated by a process running on the CPU.
-
On many systems, the logical address space is dictated by the architecture of the CPU - specifically by the number of bits in the address portion of an instruction. For example, on a machine that uses 16-bit addresses in its instructions, the logical address space would be 0 .. 65535.
-
On machines whose architecture supports relatively long addresses, logical space may be dictated by the operating system to be some subset of the potential logical space allowed by the architecture. For example, the VAX architecture utilizes 32-bit addresses, which would conceivably allow logical addresses to range from 0 .. 4 Gig; but the actual logical space allowed to any one user is dictated by system management. For example, the size of a process's page table is dictated by a management-set parameter. If this size is set at (say) 10K, then the process's logical space is restricted to a total size of 5 Meg, since each page is 512 bytes long.
-
-
physical address space
The physical address space is the range of physical addresses that can be recognized by the memory. For example, if 1 Meg of physical memory is installed on a given machine, then the physical address space would probably be 0 .. 1,048,575. (I say probably because it could just as well be installed as 1,048,576 .. 2,097,151 or 0 .. 524,287 + 1,048,576 .. 1,572,863.)
-
-
The mapping need not be one-to-one.
-
some logical address may not map to physical addresses
It may be that certain logical addresses do not map to any physical address. In the schemes we have discussed thus far, this would mean that any process generating such an address would be aborted with a memory management violation.
-
some physical addresses may not have corresponding logical addresses
It may be that more than one logical address maps to the same physical address. This would not be likely to be the case within a single process, but often occurs between processes that are sharing code or data.
-
-
Relative sizes of logical and physical memory
One question that is of interest is the relative size of the two address spaces. For the schemes we have discussed thus far, it would necessarily have to be the case that
| logical space | < | physical space |.(Recall that an attempt to use a logical address for which there is no corresponding physical address leads to abortion of the process.) This means that several entire processes can be resident in physical memory at the same time. (Recall the example of the PDP-11/70: logical space is 64K due to the 16-bit architecture of the CPU; but physical space can be as big as 4 Meg since physical addresses are 22 bits long.
Overlays
One problem that occurs over and over again in practice is that certain programs have a need for a larger logical address space than the machine they are running on will allow. Even though available memory capacities have been growing rapidly due to progress in memory chip technology, this problem never seems to go away because larger machines lead to attempts to use the computer to solve larger problems.
-
Program design
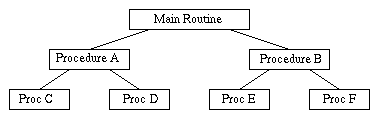
The earliest solution to this problem (and one that is still used sometimes today) is the technique of using overlays. A well designed program will have a tree-like module structure:
-
Only part of program code actually needs to be in memory at one time
Observe that, at any given point in time, it is only necessary for a single path from root to leaf to actually be resident in memory. For example, if main calls procedure A which in turn calls procedure C, then only these three routines need actually be present in memory. The remainder can be kept on disk, to be brought in as needed. For example, if C returns to A, which then calls D, then the code for D can be brought in from disk and can be put into the memory occupied by C (assuming that the code for D will fit into this space.) If A returns to main, which in turn calls B, then B's code can be brought into the space where A was.
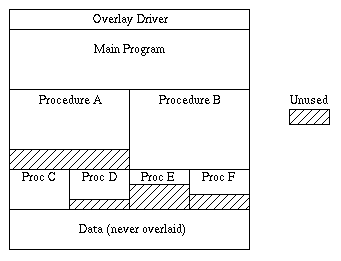
This can give rise to an overlay structure like the following, where the vertical axis corresponds to logical address space and the horizontal axis to time. The shaded regions are portions of logical space left vacant when certain shorter routines are resident to allow room for a larger routine to be brought into the space later:
-
The Overlay Manager
To make this scheme work, the compiler must translate procedure calls into calls to an overlay driver. The overlay driver checks to be sure that the desired procedure is already in memory; if not, it brings it in. Then it transfers control to the procedure. Thus, a slight extra overhead is introduced whenever a procedure is called. Note, too, that only procedure calls "down" the tree are allowed. Calls at the same level or up the tree must be forbidden, since the calling routine may be overwritten by a new overlay, which would cause the return from procedure instruction to transfer control to the wrong routine. (Of course, any procedure may contain internal procedures whose call and return do not go through the overlay driver; for these, any direction of call is allowed.)
-
Overlays are restricted to code, not data
A significant limitation of overlaying is that it only deals with the space needed for code - not the space needed for data. Thus, if a program needed a 100 x 1000 array, it could not be made to run this way on a machine that restricted it to a 64K logical address space.
Another way of solving the problem of running a process that is too big for available memory is the memory management scheme known as virtual memory. Virtual memory is characterized by having
that is, a process may potentially address more logical memory than there is actual physical memory to support it. This means that, in general, only a portion of a given process will be resident in physical memory at any one time. The part which is not memory resident will be kept in secondary storage, ready to be brought in when needed. Virtual memory is an alternate way of solving the problem addressed by overlaying - but with several major advantages over the former approach:
-
Programmer must work out overlay structure
The overlay structure for a program must be worked out by the programmer, a potentially laborious process. But virtual memory provides a form of overlaying that is invisible to the programmer.
-
Overlays are "coarse grained"
Overlay structures are typically rather coarse. There is no provision for overlaying mutually-exclusive portions of a single long procedure (e.g. different clauses in a case statement).
-
Overlays work for code, not data
Overlaying can solve the problem of a routine whose code is too big for available memory, but is of no use when the problem is the space required for data (e.g. large arrays.) Virtual memory handles either problem (or a combination of the two) equally well.
Note, however, that virtual memory requires that the underlying architecture allow for a large logical address space. That is, it only deals with the second of the two constraints on logical address space size mentioned above. A process running on, say, a PDP-11 can never address more than 64K of memory regardless of what memory management scheme is used. If a machine's architecture severely restricts the address space, then overlaying is still the only viable way of allowing large programs to run.
Virtual memory is advantageous even on systems with a lot of physical memory
Even if physical memory were large enough to hold any process that might be run on a given system, virtual memory can still be advantageous by allowing more processes to be (partially) memory resident at once, thus allowing for higher utilization of the CPU and/or allowing more interactive users to be online.
 T , T ]
T , T ]